




by Gary M. Shiffman, PhD, on Jun 16, 2021 11:36:42 AM
This article was originally published by Forbes. Click here for the full article.
According to my company's research, a full 25% of PPP fraud cases brought by the Department of Justice could have been easily prevented. The fraud is so obviously clumsy that it is embarrassing to whomever approved the loans.

Decision-makers consume a lot of data. The world is awash in data, and data is there to be used — or not used — like at no other time. As a result, risk measurement systems today perform far better than the systems of even just three years ago. But what if yesterday's performance was poor, in absolute terms? Can improvement over last year justify missing obviously blatant threats to your organization? I want to focus this article on obvious but undiscovered risk and the data not used in analytics.
Artificial Intelligence and Machine Learning (AI/ML) enable qualitative changes to risk management, which deliver large step increases in quantitative performance, leaving a gaping question. If asked, "How much improvement is enough?," then "any improvement" might sufficiently answer the question. But "any" feels like an inattentive answer. The very existence of data demands decisions most executives have not been trained to make: What data can be excluded from the analysis? And yet these decisions on what data to use and exclude require great care, like receiving a double-edged razor in an unprotected hand.
About a decade ago, when "big data" was the buzz, I remember joining industry discussions as executives rushed to formulate initiatives and responses. Leaders would often clench their fists while arguing that there is such a thing as too much data.
Too much data overwhelms humans, so the reaction of the 2010s made sense at the time. However, data also creates more accurate ML models. Amazon's market capitalization in 2011 was $78 billion and grew to an astounding $1.7 trillion by 2021; the growth came from understanding the value of more data, not less. Risk professionals in 2021 similarly understand that happiness with less data can cut a career short.
Machine Learning tools are available, posing a new "big data'' challenge for the 2020s: missing threats because of data not used. Market leaders have moved from fearing too much data to too little data in analytics.
To limit the use of data in risk discovery leaves threats undiscovered, exposing decision-makers to ex post facto criticism: "How did you miss that? It was so obvious!" The data is free and publicly available. Read news reports of PPP fraud cases, for example. People who did not have companies or employees received large amounts in Covid-19 relief dollars. "How did they miss that?" you might think. The bank and government screeners used too little data and missed obvious information. They erred in selecting the data not used.
Critics of using more data, even in 2021, rightly complain that added data still creates too many "false positives," especially in unstructured data. Like oiling a blade in a sawmill, data helps for a while but eventually gums up the moving parts. Data has a history of gumming up the risk discovery process.
To prevent these big-data frustrations in the past, data-as-a-service vendors emerged. Firms in these markets use hundreds or thousands of people to filter data, creating highly curated data sets, and they sell this high-cost data at a high price to risk professionals in many industries, financial institutions and law enforcement agencies.
Unfortunately, human-based filtering absolutely separates risk management professionals from massive amounts of valuable data. For example, financial services firms spend $180.9 billion on financial crime compliance worldwide, according to a 2020 LexisNexis study, and yet financial institutions capture less than 1% of the criminal proceeds. Fifty-seven percent of that $180.9 billion is spent on labor. The large effort masks the lack of progress.
To protect oneself from the double-edged sword of data availability in 2021, use more data in risk measurement to decrease the universe of unused data and use AI/ML to decrease the false positives challenges which vex human screeners and investigators. This is the balance to keep in mind: Use more data and reduce errors by replacing manual human curation with machine learning.
AI/ML can solve much of the double-edged nature of data abundance. Technology delivers effectiveness with efficiency. The key is reindexing the publicly available information on the internet, a task too massive for a human but easy enough for well-trained ML models, and then to perform entity resolution (ER) on that massive mess of unstructured data.
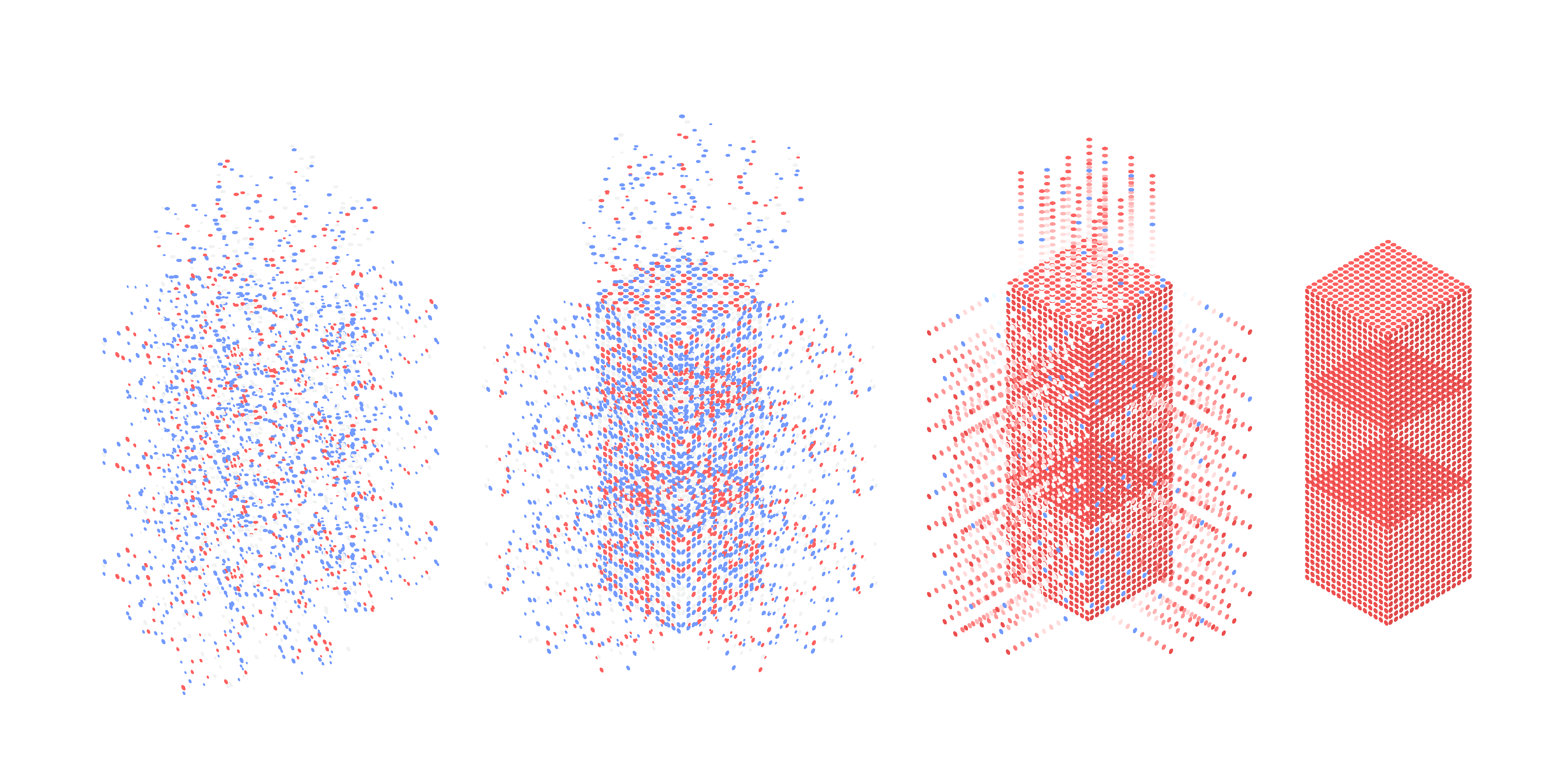
In addition, organizational changes can be implemented — for example, routine testing of ML model output with measurements of efficiency and effectiveness, such as precision and recall against a known set of test data. To do this, organizations may want to consider training management to better understand the measurement of ML systems. Including someone fluent in AI/ML performance on your company's board also makes sense in today's world of important data exclusion decisions.
If this technology exists, why is it not pervasive across every bank in the U.S.? The answer is that it takes time for the widespread adoption of new technology. There is no villain. There is no government branch or bank CEO fighting adamantly against it — in fact, joint regulatory agencies, FinCEN and the Bank Policy Institute are encouraging it. AI/ML, which is already so pervasive in our cell phones and homes, will soon start impacting the risk world, such as AML/CFT and Customer Due Diligence.
Decision-makers consume a lot of data but need the ability to use more. Entity resolution across massive public and unstructured data will soon be a part of every risk management organization. The most successful risk management managers of the 2020s will find innovative ways to utilize more data, protect privacy and improve both effectiveness and efficiency.